How to set up and run a virtual machine on Amazon Web Services
I got tired of constantly overloading my computer to the point where I couldn’t even use Word. And while I have access to a few computing clusters, some are also constantly overloaded, and some are only for working with specific confidential datasets. I needed a more general solution. So, aided by our awesome IT specialists, I set up Amazon Web Services (AWS) to run memory-intensive jobs on demand (we also use AWS for my stay-up-to-date-on-research product, Academic Sequitur). I also decided to write a brief guide for other economists who may be interested in doing this but are daunted by the switching costs.
Ex post, the process is straightforward. Because I had plenty of help along the way (thanks, Aria Novianto and David Molitor!), I claim very little credit for figuring all of this out, but any remaining errors are 100% my own. I’m erring on the side of giving too much detail, and hopefully no one will complain about that!
These instructions are for how to set up AWS to be used with “spot instances”, which utilize unused AWS capacity and cost much less to run than “on-demand instances” (up to 90% less; read more about the differences here). If you absolutely cannot afford to have your job break down at any time, you should set up an on-demand instance instead (I’ll discuss how to minimize the probability of a breakdown later on). Setting up an on-demand instance is actually easier than a spot instance, and I’ll mention the differences below if on-demand is the option you’re interested in.
To summarize, this guide will teach you how to (1) set up and customize a virtual Linux machine that you can then use anytime you want and (2) launch low-cost spot instance servers to do whatever it is you want to do. It’s meant to be self-contained, so clicking on links is optional. I was mostly interested in Python and Stata jobs, but adding R should be easy once you follow the rest of the steps. If you’re interested in RStudio with AWS, here’s a great guide for that.
Step 1: Create an AWS account
This one should be easy (go here and do your thing). FYI, your department/college may be able to create an institution-affiliated researcher account for you that makes billing your research account way easier (University of Illinois does this; ask your IT). Your menu (aka “Management Console”) should look the same as a regular account regardless.
And if you’re just starting out on AWS, you get some free stuff for the first 12 months, which is mostly useful for trying out AWS, not for actually running data jobs.
Step 2: Choose an Amazon Machine Image (AMI)
An Amazon Machine Image (AMI) is a virtual computer you can customize and launch whenever you need to. (Here’s the official AWS AMI guide.) You’ll have to pay something to store the AMI on AWS, but as long as you don’t go crazy with your customization, it won’t be much (AWS charges $0.1 per GB-month for the default General Purpose SSD (gp2) Volumes; read more here).
You can find AMIs on AWS marketplace or by searching “Public images” in the AMI menu in your EC2 console (details provided below). There’s an insane number of AMIs available. Some AMIs come pre-loaded with Python. A few come pre-loaded with RStudio (here is another useful link if you want a machine with RStudio). As far as I can tell, there are none with Stata, so if you want to use Stata, you’ll have to install it yourself (not hard ex post). I recommend searching AWS Marketplace because it seems easier, but I included instructions for both below.
Option 1: Finding and launching an AMI through the AWS Marketplace
Go to Marketplace and search for the operating system you want (e.g., “Ubuntu 18.04”). Then check “Free” in the left-hand-side panel under “Software Pricing Plan” (there may be a reason to choose a fancier non-free option, but I’m not qualified to advise you on that). I’m not an expert on all the nuanced differences in operating systems, so I chose Ubuntu 18.04 LTS – Bionic because it was the top free result for “Ubuntu 18.04”. Once you find the package you want, click on it, then click on “Continue to Subscribe”.
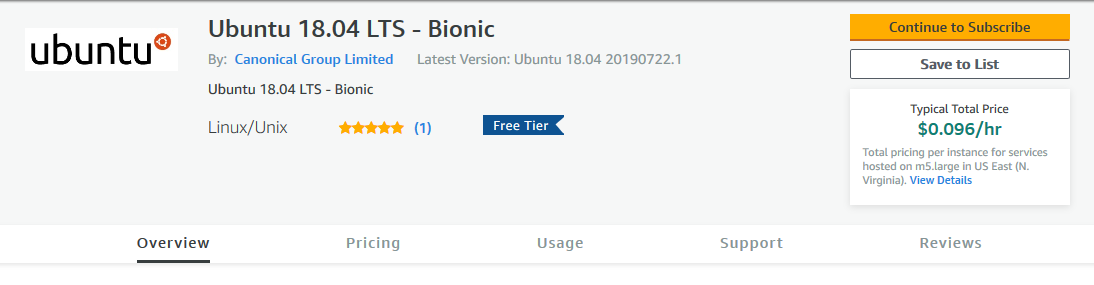
Confusingly, even for free packages it may look like you’re going to get charged something per hour (see “Typical Total Price” in the screenshot above). But that refers to the usage charges the package maker expects you to pay Amazon for running the server, not for the image itself (and we’re going to use spot instances so you’ll pay less!). Also, not all operating systems will show you these subscription screens.
On the next page, accept the terms (here you can verify that you don’t have to pay the image vendor by noting the $0/hr list prices everywhere), then wait for your subscription to be processed and click “Continue to Configuration”. Here, you can leave everything as is, but you may want to select the “Region” physically closest to you. Again, you can ignore the “Infrastructure Pricing” estimates, these will depend on how you use your machine.
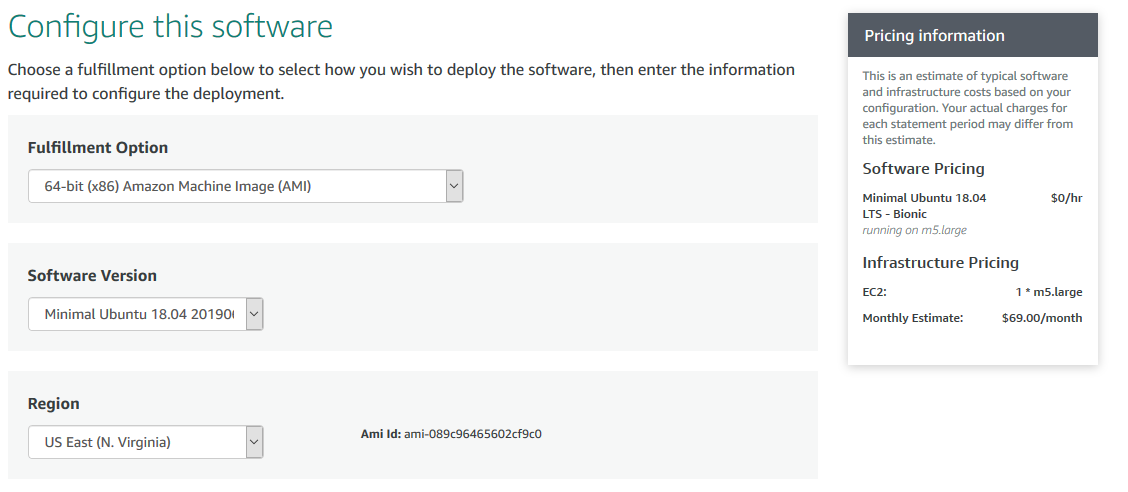
Next, click “Continue to Launch”. On the next screen, select “Launch through EC2” under “Choose Action”. Then hit “Launch” and proceed to Step 3 of this guide.
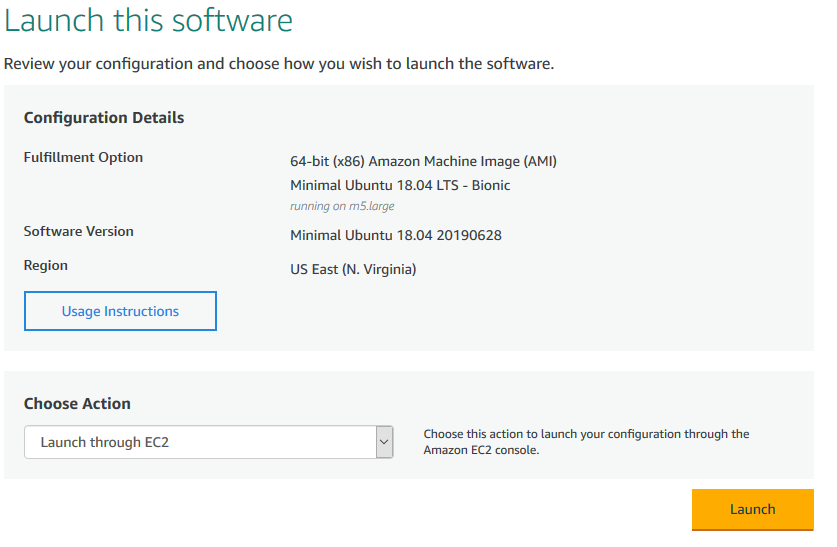
Option 2: Finding and launching an AMI through the AMI menu in AWS
Log in to your console Amazon Web Services and go to “EC2”, located under “All Services”/“Compute” (in the future, “EC2” will also show up under “Recently visited services”, as you see below).
Then click on “AMIs” under “Images” in the menu on the left-hand side. You should see something like this (I couldn’t figure out how to get the full screenshot to look nice, so this is only the left half). Select “Public Images” instead of “Owned by me” and search for the features you want your machine to have.
A word of warning here: I initially searched for “Ubuntu” and “Python” and chose an AMI that was sexily called “Deep Learning AMI” or something like that. Turned out it was 75GB in size and had way more stuff than I wanted. So my suggestion would be to go with something basic and customize it, unless you know exactly what machine you’re getting. This is why I think AWS Marketplace is better: it’s easier to see what you’re getting, whereas the results from the AMI page look like this.
But let’s say you found an AMI you like here. Select the box next to it, then choose “Actions” and “Launch”. Proceed to Step 3.
Step 3: Launch your first instance to customize the AMI
After you click “Launch” in step 2, you’ll be able to choose the “instance type”, aka how much memory/how many CPUs you want. We’re launching the more expensive on-demand instance right now, but we’ll terminate it down after we set everything up. If you’re planning on using (cheaper) spot instances, choose “t2.micro” for now – it will be sufficient for setting up programs. If you’re planning on using an “on-demand” instance that you never terminate, choose the amount of memory/CPUs you want now, keeping in mind that the more you select, the more you’ll pay per hour (generally, the charges scale linearly with memory; see here for pricing).
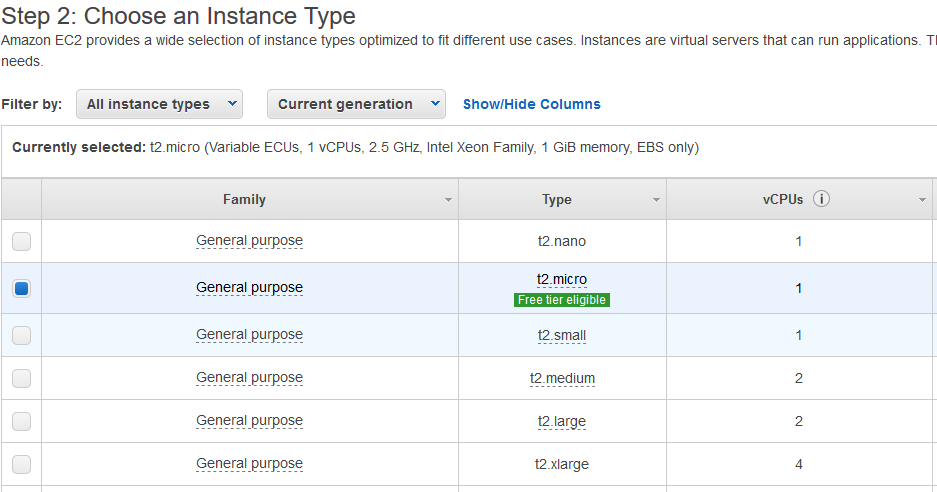
Unless you’re a computer guru, you’ll probably want to click the “Review and Launch” button now instead of “Next: Configure Instance Details”. You also shouldn’t have to change anything on the review screen that comes up next, so you can just hit “Launch”.
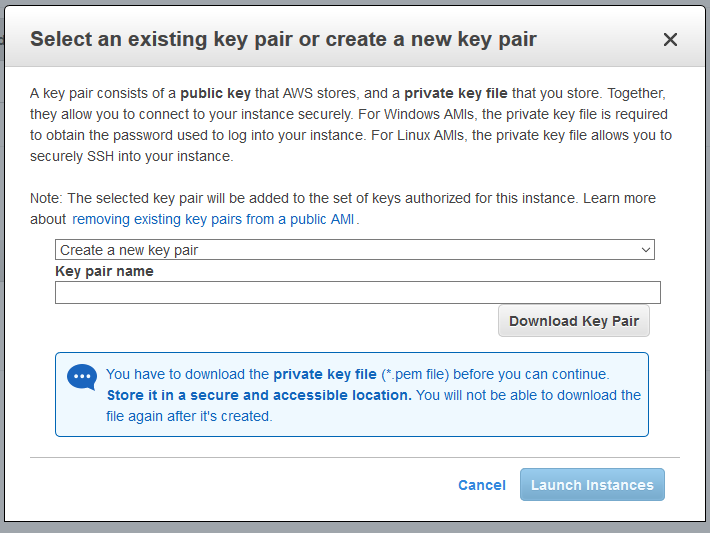
Next, you’ll be prompted to select a key pair or create a new one. Select “Create a new key pair”, name it, and click “Download Key Pair”. The file will be a .pem file, and you should keep it in a safe accessible place on your computer. After you’ve downloaded the key pair, click “Launch Instances”.
Once you see a confirmation that your instance has launched, click on “View Instances” to go to your instance details. You can also get there from the main Management Console by going to “EC2” and clicking on “Instances” in the left-hand-side menu. Note the Public DNS (IPv4) of your instance, something like ec2-35-172-201-106.compute-1.amazonaws.com below (don’t worry, this particular instance is long gone now). You’ll need this IP and the key to connect to your instance and customize it.

Step 4: Connect to your instance and customize your AMI
Use your favorite SFTP client and terminal emulator to connect to and work with your new instance. I use FileZilla and SecureCRT, respectively, so I’ll include brief instructions for these. Most likely, instructions for your favorite client/emulator will be similar.
FileZilla
- In FileZilla, click on “File”, then “Site Manager”.
- Click “New site” on the bottom left and give it a name.
- In “Host”, paste the Public DNS of your instance.
- For “Protocol”, select “SFTP”.
- Write “ubuntu” in the “User” field.
- For “Logon Type”, select “Key File”.
- Click “Browse”, navigate to the “.pem” file you saved earlier (Filezilla may default to looking for “PPK files”, so switch it to “PEM files” if you don’t see your key where it should be).
- Click “Connect”.
- Select the “Trust this Hostkey” checkbox and click “OK” when you see the “Unknown host key” warning.
You should now be in the /home/ubuntu directory.
SecureCRT
- Click on “Quick Connect” (Alt+Q).
- In “Hostname”, paste the Public DNS of your instance.
- Write “ubuntu” in the “User” field.
- Under “Authentication”, de-select everything except “PublicKey”.
- Click on “PublicKey” (not the checkbox) to highlight it, then click “Properties”.
- Select “Use session public key setting”.
- Click “…” under “Use identity or certificate file” (which should be selected) and navigate to the “.pem” file you saved earlier.
- Click “OK” and then “OK” again.
- Double-click on the new session & “Accept & Save” when the host key warning comes up.
Installing software
You should now be connected through both the SFTP client and the terminal emulator. If you’ve installed Linux programs before, and you know what to do, just do your thing and then skip to Step 5. If you’ve only used Linux servers that came pre-loaded with programs on a silver platter (like me!), keep reading. I’m going to go through how to install Stata (it’s not hard). Good Anaconda instructions that I followed are available here, if you’re interested. To install R, follow these instructions. Note that you need to make sure to choose the version of R appropriate for your OS, in this case, Bionic Beaver.
Stata
To install Stata on your new virtual machine, you need an individual license, which I’ll assume you have. Go to the Stata website and use the login information you got when you bought Stata to access and download Linux installation files. On the download page, you’ll also see the installation instructions. Here’s a version of them.
First, copy the “Stata16Linux64.tar.gz” (or whichever installation files you downloaded) into /home/ubuntu. Then execute the following commands
- sudo -s (this makes you a superuser)
- cd /tmp/
- mkdir statafiles
- cd statafiles
- tar -zxf /home/ubuntu/Stata16Linux64.tar.gz
- cd /usr/local
- mkdir stata16
- cd stata16
- /tmp/statafiles/install
The installation will now start. Click “y” to continue and follow Stata’s instructions. They’re pretty straightforward. At some point, you have to enter your license information, etc. The most important thing is to verify that Stata installed successfully by typing “./stata” after the installation steps are complete (which Stata will tell you to do as well).
To have “stata-mp” or “stata” work for launching Stata from command line, type:
echo export PATH=”/usr/local/stata16:$PATH” >> ~/.bashrc
source ~/.bashrc
You can also add data and scripts to your AMI at this point, but unless you want to save them on AWS even when your programs aren’t running, wait until we get to spot instances. It is a good idea to create directories, such as “research/scripts”, “research/data”, etc, so you don’t have to create them each time. If, however, you decided to run an “on-demand” instance, you can stop reading and start adding data and running your jobs! As long as your instance is running, all your data/programs are safe and you don’t need to save the machine image.
Step 5: Save your updated AMI
Once you’re done customizing your AMI, go to “Instances” under “Instances” in your main EC2 menu. Check the box next to your instance, choose “Actions”, then “Image”, then “Create Image”. This will create and save an AMI that you’ll be able to use in the future. All you have to do is name it and decide how much storage you need for the instance under “Size (GiB)” (I’m guessing it’s fine leave the other options at their default). Running “df -h” in your terminal window will show you how much space is being used on your instance, so you can avoid using more than necessary.
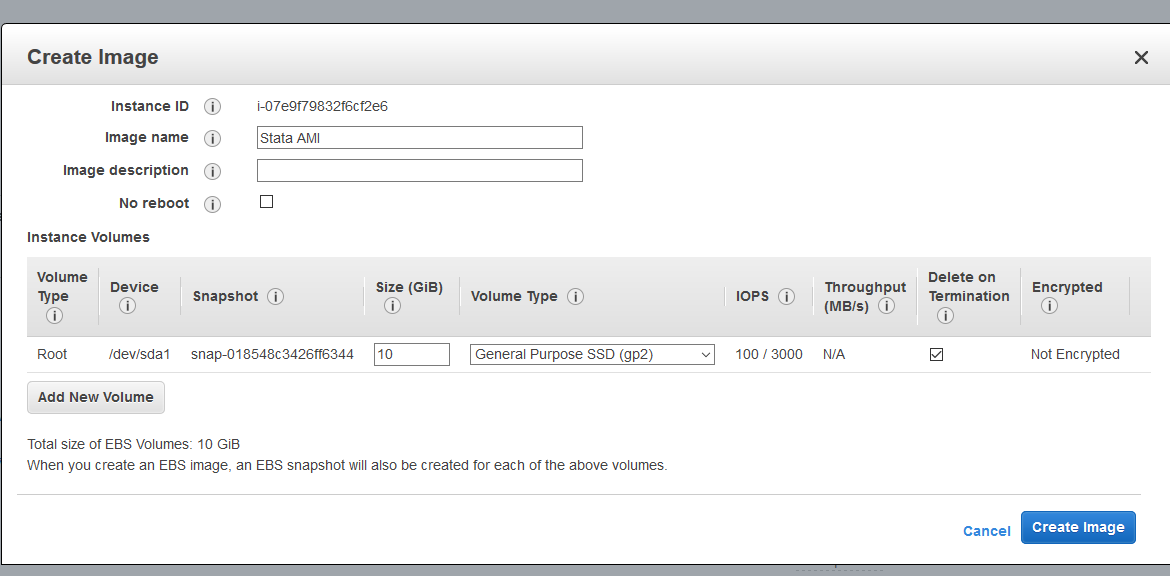
Your AMI will now be visible under “Images”/”AMIs” in the main EC2 menu. It may take up to 15 minutes to create, and you should confirm the AMI has been created before terminating the spot instance. Once it’s finished (status=”available”), we’re going to shut down the “on-demand” instance we’ve been running so far (which is the more expensive one and will keep on running unless you shut it down). Then, we’re going to move onto spot requests and adding data/scripts.
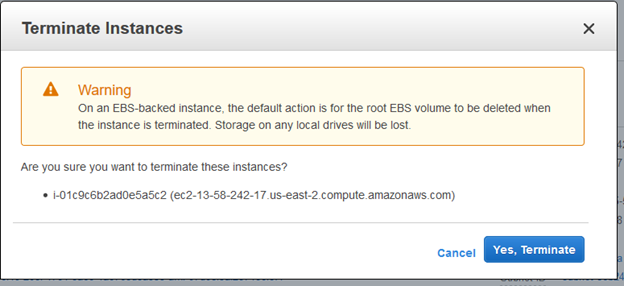
To shut down your instance, select it on the “Instances” page, then choose “Actions”/“Instance State”/“Terminate”. You’ll see the warning below, but because you saved your instance as an AMI, you’re ok to terminate and delete the root EBS volume of the instance itself.
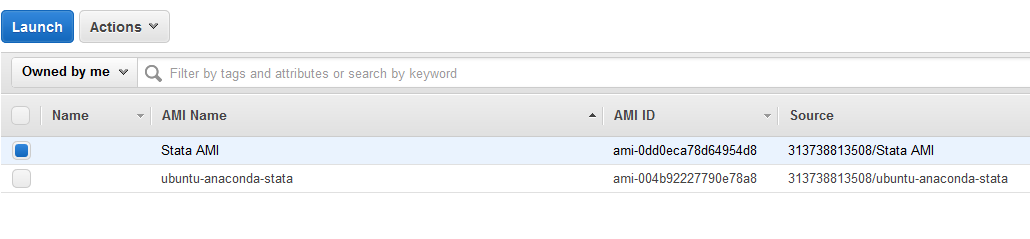
Step 6: Launch a Spot Instance and do your work!
Go to “Images”/”AMIs” in the main EC2 menu. Select your AMI, click on “Actions” and then “Spot Request”.
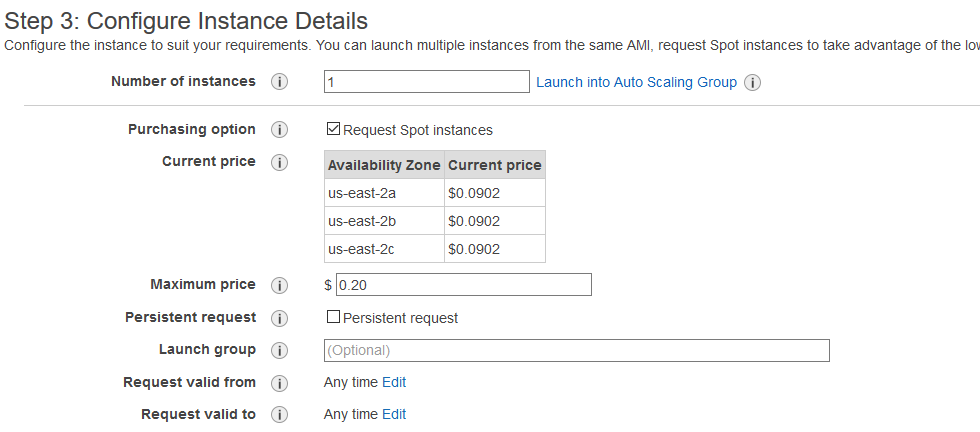
The next screen will look just like the one you saw when you were launching the AMI for the first time. Now, however, choose the amount of memory/CPUs you want for the job you’re planning on running. Click “Next: Configure Instance Details”. You’ll see the current prices for spot instances in your region. Here, an important choice to make is the “Maximum Price” field. Basically, a spot instance will stop if the hourly price exceeds your maximum price. I haven’t yet figured out how much prices fluctuate, but an obvious fact is that the higher you set your “Maximum Price”, the lower the probability that your instance will be stopped. And my guess is that any large increases in price are unlikely to be long-lasting, so it may well be worth it to ride them out. But I’ll report back once I have had a chance to use spot instances more.
You can also select “Persistent request”, in which case you can have your instance “Stop” instead of “Terminate” (there’s a theoretical “Hibernate” option, but it’s never actually been available on any of the spot requests I’ve experimented with). Given that it’s not hard to launch spot instances, I didn’t see any reason to choose this option.
Click “Next: Add Storage”. Decide how much storage you want and click “Review and Launch” (you probably have no reason to use the “Tag Spot Request” option). Click “Launch”, choose the key pair you generated earlier, check the checkbox, and click “Request Spot Instances”. You should see the screen below (if you get an error message at this point, just click the “retry” button).
Now you can click “View Spot Requests” on the right side of the screen. To actually connect to your server, you’ll now want to go to “Instances”. Use the Public DNS of your new instance and the directions in step 4 to connect to the instance. Your programs and everything else you did when you set up your AMI should be preserved in the exact same state as you saved it! And instead of creating a new connection in your SFTP/terminal emulator, you can just edit the IP address of the old one, and everything will work if you’re using the same key.
Voila! Now you can go nuts and add new folders/data/scripts to your “/home/ubuntu” directory, run your jobs, etc. Once you’re done with your work, you should select the spot request, click “Actions”, then “Cancel Spot Request” and leave “Terminate instances” selected. This will automatically shut down the instance as well and delete the EBS storage volume you created. Any changes you made on the server since launching your AMI will NOT be saved, so make sure you download the results of your work! If you do want to save your work, you can just repeat what we did in Step 5 and save your instance as a new AMI (but, again, if you leave a lot of data lying around, you’ll be paying for it).
Repeat Step 6 as necessary to run your jobs.
Final notes
If you update your machine image several times, you’ll end up with quite a few AMIs, and you’ll be paying for that storage. You can de-register old AMIs you don’t need (under “Actions” in the AMI menu), and you should also delete them from storage. To do so, got to “Snapshots” under “Elastic Block Storage”, select the Snapshot corresponding to the AMI you want to delete (I just go by date created and keep the most recent snapshot) and choose “Actions”, “Delete”.
A random word of warning: everything in AWS is region-specific. So if you go to your console and you can’t find your instances/AMIs, you may be in a different region than the one you used when you created them. To switch regions, just click on the middle down arrow on the right-top corner of your console and choose a different region. In general, it’s a good idea to choose the region physically closest to you (in my case, it would be Ohio, not North Virginia, as shown below).

Another random word of warning: when setting up your AMI, don’t be too stingy with disk space. I initially launched an AMI with 8 GiB of space and ran out of disk space in the middle of installing something. Long story short, I had to start over again.
Future adventures
A mild downside of this setup is that the storage space you use for your AMI will cost you whether you’re running spot instances or not. It’s not a lot if you have a moderate amount of data, but for large datasets it can add up. There are cheaper storage options on Amazon (read about these cheaper options here), but they are a bit more complicated to set up and accessing them requires modifying your scripts. Everything above relies on so-called Elastic Block Storage (EBS). I’m told by my colleague that uses the cheaper storage type (S3) that it’s pretty straightforward, but I haven’t had time to delve into it yet, so I’ll leave it for a future post.





Comments are closed.